Distilling Knowledge in a Neural Network
by maya
Sponsored Link
Deep Learning の世界で Distillation という単語を初めて使ったGeoffrey Hinton, Jeff Dean らの論文を紹介します. Distillation を調べる上ではやはり最初に読むべき論文でしょう. Distillation についての基本的な知識やサーベイ対象論文一覧はこちら.
概要
本論文の貢献は以下にまとめられます.
- 温度つきSoftmax cross-entropy による大規模モデルから小規模モデルへの知識の転移手法 Distillation を提案
- Distillation の学習方法を応用して,複数のSpecialist Models を併用する新しいアンサンブルに学習する手法を提案
- 上記2つの提案手法の効果を,画像認識タスク, 音声認識タスクで確認
背景が長くてなんだか目が滑る論文ですが,ちゃんと読んでまとめていきます.
Motivation
小さなモデルサイズと高い性能の両立
Deep Learning では所望の精度を達成するために巨大なネットワークを大量のデータで学習する必要があります. そのため,必然的に学習時間がかかるものですが,幸いにして学習フェーズにおいてはリアルタイムに学習する必要はありません.
しかし,推論フェーズでは,学習済みモデルを利用してユーザに対してサービスを提供するとき,latency や計算リソースに対して制約が現れます. したがって,実用的な運用のためには巨大なモデルは避けて極力小さいモデルを使ってシステムを構築したいと考えるのが自然です. 一方で,一般的にニューラルネットワークのパラメータ数や層数が小さくなると,それらが大きい場合と比べて性能が劣ることが知られています. このままでは性能・コストの面で実用的なアプリケーションをつくることができません.
そこで,なんとか小さいモデルで大きいモデルと同等の精度で推論を実行できるようにしたいというのがこの論文のモチベーションです.
Challenge
巨大なモデルから小さなモデルへの知識の転移
モデルサイズと性能の両立という課題を解決するための手法として 巨大で複雑なモデルの知識を小さくシンプルなモデルに転移する Model Compression が提案されています.
Model Compression は学習済みモデルのパラメータに “知識” が存在すると仮定しており,ラベルなしデータを介して知識の転移を試みています1. しかしこの手法では,cumbersome model から得られる情報(予測確率など) を small model に直接的に転移させているわけではありません. そのため,cumbersome model が持つ知識を保ったまま,small model をどのように変形すれば良いのかという観点では不十分なのではないか,というのが本論文の主張です.(と,私は解釈しました.)
わかりやすさのために,以降では転移元の巨大なモデル (上記のcumbersome model) を Teacher, 転移先の小さいモデル (上記のsmall model) を Student と表記します. (これは論文の表記とは異なります.ご注意ください.)
Distillation
直感的理解
ではこの論文のキーとなるアイデアを紹介していきます.
本論文では,モデルの知識が入力から出力への写像によって獲得されるものであると考えます. つまり,ニューラルネットワークに対して特定の入力を与えたときの出力に有益な情報が存在していると解釈します.
Distillation は, Teacher の出力(予測確率)を使ってStudent の学習を行う手法です. ここでは具体例として分類モデルについて考えます. 通常の分類モデルでは,確率正解ラベルに対する対数尤度を Softmax cross-entropy で最大化して学習を行います.
この副作用として,不正解ラベルに対する予測確率も得られます.
例えば,正解ラベルがスポーツカーだったとき,同時に正解でないトラックや人参のような不正解のクラスラベルに対する予測確率を得ることができます.
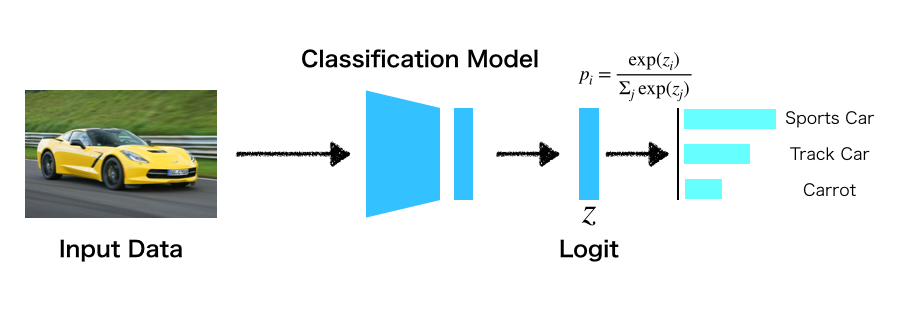
著者らのアイデアは,不正解ラベルに対する予測確率を利用することにほかなりません. つまり,Student は Teacher の予測確率全体の分布を模倣することで Teacher に近い出力を得られるように学習することができる(=知識を転移できる)ということです.
例えば先程の例なら,スポーツカー がモデルに入力されたとき,(よく学習ができているならば)もちろんスポーツカーラベルへの予測確率が最も高くなるはずですが,
トラック への予測確率は人参 よりも相対的に大きくなっていると考えられます.
Distillation で行いたいことは,Teacher モデルと Student モデルの全ラベルに対する予測確率の分布をマッチさせることです.
論文ではこの全ラベルに対する予測確率の分布が Teacher モデルの汎化の傾向を表しており,転移させるべき知識を司っていると考えています.
ですから当然ですが, Teacher はテストデータに対して高い汎化性能を持っていることを仮定しています.
温度付きSoftmaxによる Student の学習
ここまででDistillation がやりたいことの直観を理解できたので,次に具体的な学習方法を見ていきたいと思います.
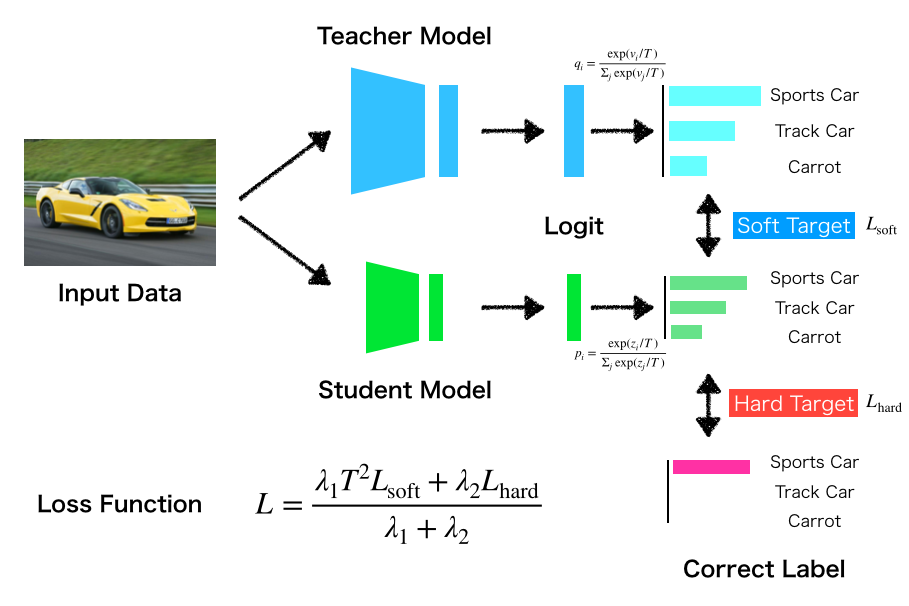
図はDistillation による学習の全体を表したものです. Student は次の2つの損失項で最適化されていきます.
soft target: Teacher の予測確率と Student の予測確率を近づける項hard target: 正解ラベルと予測確率を近づける項(普通の Softmax cross-entropy)
このうち,soft target は,特定の入力に対する学習済み Teacher モデルの予測確率と,Student モデルの予測確率が近づくように,次の式でSoftmax cross-entropy を計算します.
ただし,このときの各予測確率は,
と計算されます.これが温度付きSoftmaxです.式中のは温度パラメータ,はそれぞれ Teacher, Student の logit (softmax への入力となる特徴マップのこと.シグモイドの逆関数ではない)を表します.
温度付き Softmax を使う理由は,この手法が不正解ラベルの予測確率に注目していることにあります. 通常の Softmax関数は単に入力の指数関数から計算されるので,Teacher から得られる予測確率は正解ラベルについて高く,相対的に不正解ラベルはとても小さいものになってしまいます. これでは,汎化傾向に関する情報が含まれていたとしても正解ラベルの予測確率に対して微小なので学習時に反映されず,あまり意味がありません. そこで,温度付き Softmax を導入し,温度パラメータをに設定することで(本来低く現れる)不正解ラベルに対する予測確率を強調して学習を行います. 温度付き Softmax についてはこちらの記事が大変参考になります.
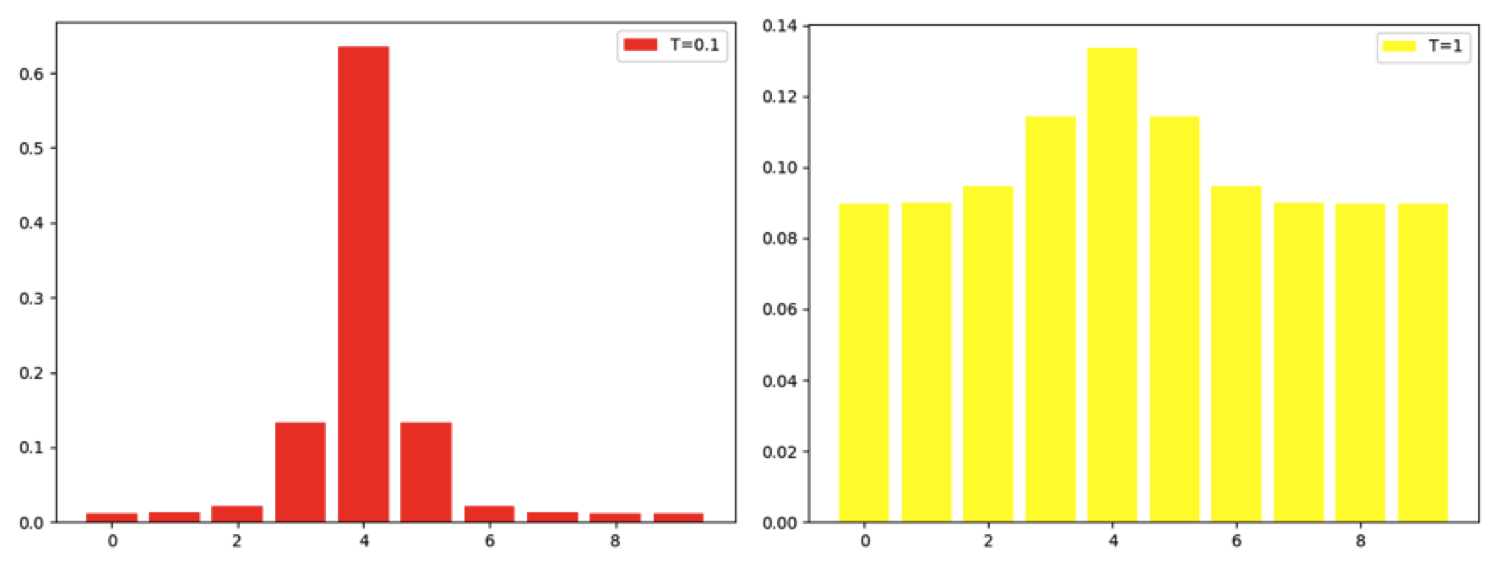 温度付きSoftmax の温度パラメータTによる出力の差異(Source)
温度付きSoftmax の温度パラメータTによる出力の差異(Source)
この温度付き Softmax を利用するのは soft target 計算時のみであり hard target では,つまり通常の Softmax を計算します.
最終的な目的関数はsoft target と hard target の加重平均で計算されます.
論文ではとすることで最も良い結果を得たと報告しています.
また, を にかけているのは,温度付き Softmax によって勾配がにスケールされてしまうので,hard target とのスケールをあわせる必要があるからです.
論文には書かれていませんが,提案手法を Distillation(蒸留) と名付けたのは比較的高い温度係数を使って温度付き Softmax を計算するからではないかと思います.
既存手法との関係
Distillation のように,Teacher モデルの出力を利用する手法は他にも存在します. 特にCaruana らによる,Teacher と Student の logit の二乗誤差を最小化する手法は本研究と関連が深いとされています. 今,Teacher と Student の各 logit の値がで与えられるとして,その二乗誤差は
で計算できます. 論文では,このlogit による手法が,Distillation の特殊ケースであることを示しています. この導出を少し追ってみたので,ここでは解説を試みます.
Distillation の soft target はクロスエントロピーで計算できます. 今,Teacher と Student の予測確率がそれぞれで与えられるとき,そのクロスエントロピーは,
をについて偏微分すると,
ここからは高校数学の復習です.
指数関数は,
で表されます.また,のとき
つまり,
が成り立つ.
ここで,でのとき
と近似できる. すなわち,温度係数がと比較して十分大きいとき,は,
と書き換えられる.
もし,入力に対してlogit の各成分の平均値が0であるとき,となり,最終的に偏微分の式は
に簡略できる.
このようにして,色々と条件をくっつけたものの,温度付き Softmax のクロスエントロピーの式から二乗誤差の偏微分を導くことができます.
Experiments
それでは,Distillation の効果を確かめる実験を見ていきたいと思います.
MNIST での予備実験
論文では,まず予備実験として MNIST での分類実験を行っています.
実験結果は次のようにまとめられます.
| # of layers | # of hidden units per layer | Test error cases | |
|---|---|---|---|
| Teacher | 2 | 1200 | 67 |
| Student | 2 | 800 | 146 |
| Student (Distilled) | 2 | 800 | 74 |
Soft target によって Distillation された Student モデルは,Teacher モデルに匹敵する精度を得られていることがわかります. ちなみにこのときの温度係数はです.
この温度係数について,一層あたりのユニット数が300以上であれば8以上を設定するとうまくいく一方で, 30以下の小さな Student モデルではで学習が改善するというデータも報告されています. このあたりはケースバイケースで変わってくるので,ハイパーパラメータとしてチューニングする必要があると考えられます.
Speech Recognition
ここでは Automatic speech recognition タスクを通して,アンサンブル学習と Distillation の比較を行っています. アンサンブル学習は機械学習における一般的なアプローチであり,複数のモデルの予測結果から総合的に予測結果を導く手法です.
実験では同じネットワークを持つ10のモデルを別々に学習し,それをアンサンブル学習で利用する場合と,Distillation で1つのモデルにまとめた場合を比較しています. ここで,Distillation 時には10の学習済みモデルを Teacher とし,同じネットワーク を持つ Student を学習していることに注意してください.
以下が結果となります.
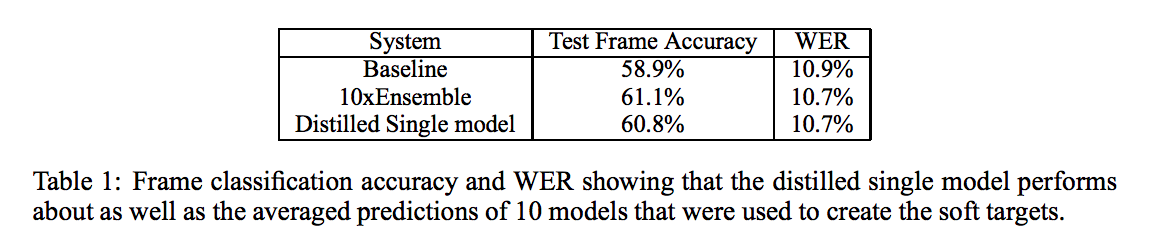
1つのDistilled モデルが10の学習済みモデルを必要とするアンサンブル学習の結果とほとんど同じ性能を発揮できていることがわかります.
Specialist によるアンサンブル学習
次に,Distillation を使って,特定のサブカテゴリに強い Specialist を複数学習することで,通常のアンサンブル学習よりも効率的に巨大なデータセットを学習できる手法が紹介されています.
この実験で利用する データセット JFT は Google の内製データセット(おそらく今も非公開?)で100万枚,15,000ラベルを持つ巨大なデータセットです. 先程の実験では Teacher をアンサンブルにすることで精度を改善することができました. しかし,JFTのような巨大なデータセットをまともに学習できるようなフルサイズのモデルを愚直にアンサンブル学習すると,法外な計算量を要求されてしまいます.
そこで,この論文では,データセットラベルを分割して,細かい違いを認識できる Specialist モデルを学習し,それらから成るアンサンブルモデルを構築することを考えます. こうすることで,フルサイズのラベルを学習する通常のアンサンブル学習よりもコストを下げることができます.
ここでは簡単な紹介に留めますが,Specilist モデルをを作成する過程でも様々な工夫を施しています.
- Specialist モデルは Generalist モデル (すべてのデータセットで学習したモデル) を Fine-tuning
- Specialist が担当するクラスラベルのサブセットはGeneralist モデルの出力の共分散行列を用いたクラスタリングアルゴリズムで自動生成
- 学習時はまず入力に対する Generalist の予測ラベルを出力し, Specialist の全体集合からそのラベルを担当する Specialist 群をピックアップして学習
- 学習時は Generalist と Specialist の両方を次の目的関数を最小化することで学習
ここで,は Generalist モデルの soft target による予測確率であり,は(おそらく Generalist モデルを用いて) hard target で計算された全ラベルの予測確率です. この目的関数をSGDで最適化していきます.
実験では61の Specialist モデルを追加した場合の精度測定をまず行っています.
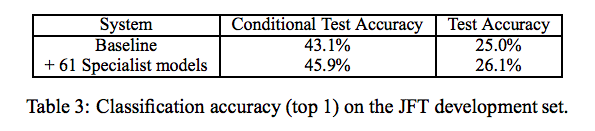
Test Accuracy が改善していることがわかります. Conditional Test Accuracy は,ラベルを担当すると考えられる Specialist だけを使ってアンサンブルした推論結果となります. おそらく,Generalist の予測結果を使っているものと考えられます.
次に, 担当する Specialist の数を増やした場合についての評価です. 今回の場合,クラスラベルのサブセットは互いに素な集合ではないので,一つのラベルに対して複数の Specialist が存在します. 下図の結果では Conditional Test Accuracy を計測する際に選択できる Specialist の数を増やして実験を行っています.
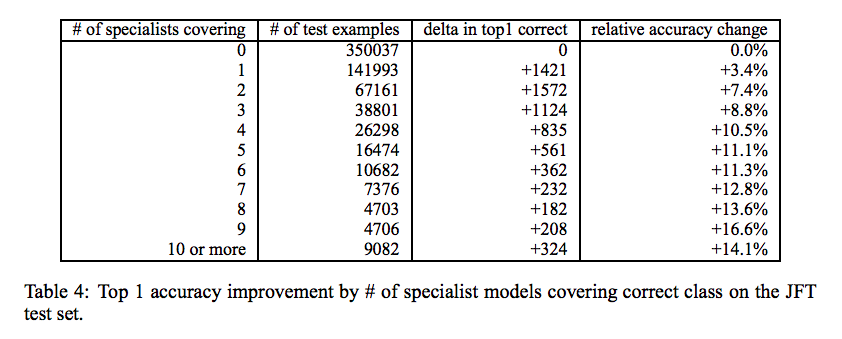
Specialist の数を9まで増やしていくと最大の効果を得られていることがわかります.
Soft target の正則化効果について
著者らは soft target が効果的なのは hard target よりも役立つ情報(予測の傾向)を含んでいるからであるとし, 小さなモデルに知識を伝えるだけでなく,必要なデータ量を削減できることを主張しています.
例えば,Speech Recognition の実験では 3%のデータ量において soft target で学習した場合, 100%の Baseline と同等の精度を達成することができます.
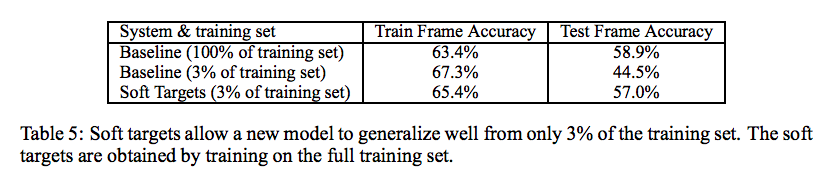
また early stopping も必要なく,自然に収束する(過学習しにくい)性質にも言及されています. ただし,Speech Recognition のデータセットは3%でも2,000万件と,一般的には巨大なデータセットであることに注意が必要です. (当たり前ですが,なんでも3%になるわけではないです.)
さらに, Specialist を学習する場合も soft target は過学習を防ぐことができるし,データ量を削減できると主張しています.
混合エキスパートモデルとの関連について
最後に,Specialist を使ったアンサンブルモデルと混合エキスパートモデルとの関連について触れています.
混合エキスパートモデルも,今回挙げた Specialist によるアンサンブル学習のように,複数のモデルからの出力を集約し,ゲート関数で最終的な出力を決定します.
このゲート関数は各入力例に対してどのエキスパートからの出力を選択するかの予測確率を学んでいきます.
したがって各エキスパートを同時に学習する必要があるので,並列化が難しいことが懸念点として挙げられます.
一方で,Specialist を用いたアンサンブル学習は並列化が容易であると主張されています. 各スペシャリストが担当するサブカテゴリは,Generalist モデルの出力の混同行列で決定されます. 一度サブカテゴリが決定されてしまえば,学習に関連する Specialist は限定されるため独立に各スペシャリスト群を学習することができるということです.
要するに,混合エキスパートモデルとの違いは,Generalist→Specialist の二段構成になっていることであり,これによって学習がしやすくなっているという主張であると解釈できます.
感想
このサーベイ企画のコアとなる Distillation を提案した元論文を読みました. 構成が簡単でわかりやすい論文を読むのに慣れてしまっているからか,読むのが結構しんどい印象でした. まとめるのに予想外に時間がかかってしまった. 新しい概念を提案するときはこのような書き方になるのか,これが Hinton 先生節なのか…
さて,これからDistillation系論文をどんどん読んでいきたいと思います. 間違っているところなどがあれば,気軽にコメントいただけると大変ありがたく思います.
参考文献
-
具体的には まずlabeled data で学習した高性能モデルの出力確率を使って unlabeled data をラベリングして pseudo dataset を形成する(MUNGE アルゴリズム).次にその pseudo dataset を使って小さなモデルを学習する.要するに未知のunlabeled data を経由して高性能モデルから小さなモデルに知識を転移させるわけです.詳細は割愛. ↩
Subscribe via RSS