Distillation - Survey Top
by maya
Sponsored Link
Distillation に興味があるので,関係する論文を調べていきます.
論文を紹介する前に,前提知識(背景)を自分なりにすこしだけまとめておきます. 技術の全容をよりわかりやすく丁寧に俯瞰したい方はこちらの素晴らしい記事を読むと良いです.
(ヘッダ画像ソース: Knowledge Distillation by Ujjwal Upadhyay - Mediam)
Distillation について
機械学習,特に深層学習におけるDistillation(蒸留) とは,ざっくり言うと巨大で複雑なモデルで獲得した知識を使って,より小さなモデルを高精度に学習する技術です.
なぜ小さいモデルで高精度に学習がしたいかといえば,推論環境ではリアルタイム性や省リソース性が求められているからです. GPUなどを潤沢に使用できることが学習フェーズとは対照的に,学習モデルを実際に利用する推論フェーズではコストやサイズの観点から,より簡易なマシン環境でタスクを捌きたいという要求があります (e.g., 監視カメラに搭載された組み込み推論チップ, TensorRTとか). 当然ですが精度の高い巨大なモデルはこのような簡易な環境に搭載することは難しく,載せられたとしても今度はスループットが問題になってきます.パラメータ数が多ければ自明に演算回数も増えるからです.
では,最初から小さいモデルで学習を行えばよいのでしょうか?巨大なモデルと同じような精度が達成できるならばそれも良いでしょう.ただし,一般的にはネットワークパラメータが少ないほどモデルの推論精度が下がることが知られています.
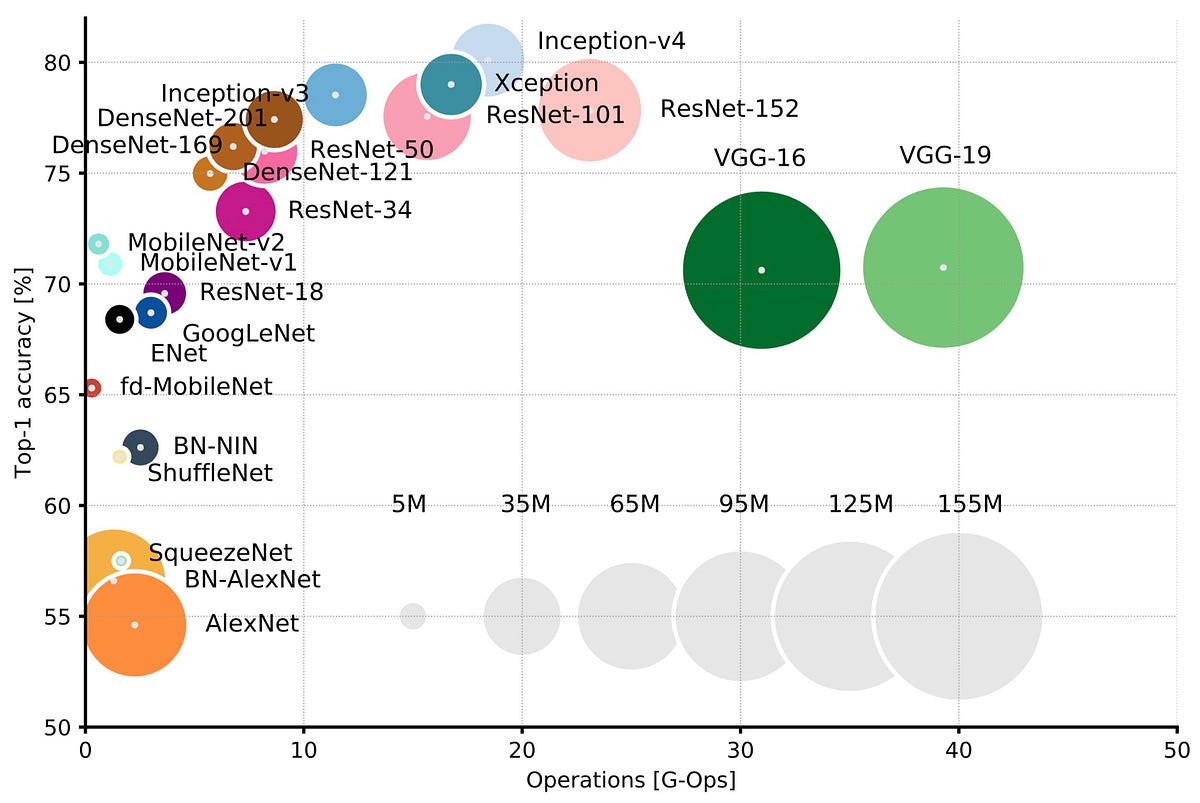 ネットワークパラメータ数と精度の関係(Neural Network Architecturesより)
ネットワークパラメータ数と精度の関係(Neural Network Architecturesより)
Distillation はこのようなモデルサイズと精度の両立という推論環境特有の要求にマッチしている手法と言えます. 基本的には,まず巨大で複雑なネットワークを学習し,学習済みモデル(Teacher)を作ります. その後,Teacher モデルの出力(予測確率や特徴量)を小さいモデル(Student)を学習するときの損失に組み込むことで,Teacher が持つ知識をStudent に教えてあげることができます.
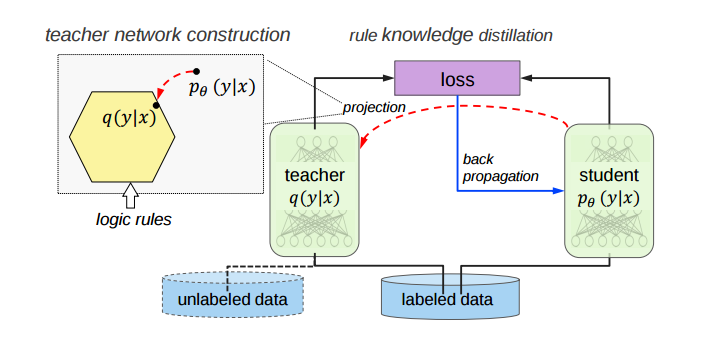 Distillation のしくみ (Knowledge Distillation - Mediamより)
Distillation のしくみ (Knowledge Distillation - Mediamより)
Teacher のドメイン知識をStudent に転移させているわけなので,Distillation は一種の転移学習とみなすことができます.(転移学習についての厳密な定義をこの記事では述べません.機会があれば解説に挑戦したい.) このときの知識の転移をどのようにして行うかが Distillation に関係する各論文のアイデア(オリジナリティ)になっているはずです.
サーベイの対象
このブログでは以下の論文についてのサーベイを行い,それなりに時間はかかるかもしれませんが一つずつできるだけ丁寧にまとめていきたいと思います.
- Distilling Knowledge in a Neural Network [1]
- FitNets: Hint for Thin Deep Nets [2]
- Deep Mutual Learning [3]
- Knowledge Concentration: Learning 100K Object Classifier in a Single CNN [4]
以下,準備中
- Data Distillation [5]
- Born-Again Neural Networks [6]
- MEAL: Multi-Model Ensemble via Adversarial Learning [7]
- A Gift from Knowledge Distillation: Fast Optimization, Network Minimization and Transfer Learning [8]
- Progressive Blockwise Knowledge Distillation for Neural Network Acceleration [9]
- Knowledge Distillation by On-the-Fly Native Ensemble [10]
- Dataset Distillation [11]
- Adversarial Distillation of Bayesian Neural Network Posteriors [12]
- Teaching Semi-Supervised Classifier via Generalized Distillation [13]
- Learning from Noisy Labels with Distillation [14]
- Cross Modal Distillation for Supervision Transfer [15]
- Dropout Distillation [16]
- Self-supervised Knowledge Distillation Using Singular Value Decomposition [17]
(順次更新予定)
オーソドックスな手法はCode Craft House様がまとめてくださっているので,私は新しめの論文を中心にサーベイしたいと思います. また,特定タスク向けのチューニングにはあまり興味が無いのでなるべくタスク依存でない手法を選んでいます. 面白そうな論文があったら追加していきたいと思います.
Subscribe via RSS