Knowledge Concentration
by maya
Sponsored Link
Distillation 企画 4本目の論文 Knowledge Concentration: Learning 100K Object Classifiers in a Single CNN を紹介します. 内容は,複数の Specialist Teacher から,たった1つの Student に知識を転移する手法です.
タイトルは直訳すれば知識の集約ですが,1万クラスもの巨大なデータセットに対してどの様にモデルを学習させていくのか,通常の Knowledge Distillation との違いはなんなのか等,とても興味をそそられる論文です.
概要
本論文の貢献は次のようにまとめられます.
- 特定のカテゴリに強い複数の (Specialist) Teacher が持つ知識を,一つの Student モデルに集約する
Knowledge Concentrationを提案 - Knowledge Concentration では,通常の Knowledge Distillation に
self-paced learningメカニズムを導入することで,カテゴリにあった学習のペースを適応的に決定 - さらに,
structurally connected layerを追加することで,少ないパラメータ数でネットワークの表現力を拡張 - 新たに作成した10万クラスラベルを持つデータセット
Entity-Foto-Tree(EFT)において劇的な精度改善を確認
どうやらやっていることは過去に紹介した Knowledge Distillation ベースのアプローチのようですが,
self-paced learning や structurally connected layer など,大規模データセットに対応させるための工夫が詰まっていそうです.
Motivation
より広く,より細やかなクラス分類を実現したい
 ImageNet-1Kの階層的なクラス構造 (Source)
ImageNet-1Kの階層的なクラス構造 (Source)
本研究のモチベーションを一言で書けば,広範かつ粒度の細かい(fine-grained)クラスを認識可能なモデルの学習となります.
なぜそのようにきめ細やかな分類を行う必要があるのでしょうか? その理由は実用上の強い要求にあります.
通常,画像認識系の論文で登場するようなクラス分類といえば,CIFAR10/100 や Stanford Cars, Bird Snap などのベンチマーク用のデータセットで数十〜数百クラス,多くてもImageNet-1Kの1,000クラスで評価を行うことがほとんどです. しかし,今日広く利用されている画像検索やAIアシスタント等の実用的なアプリケーションでは,より多くの,より細分化されたクラスを判別する必要があります.
例えば,ユーザが雑貨屋で「OK Gxxgle,このお皿について教えて」とAIアシスタントを利用する場合を想像してみてください. もしアシスタントアプリの返答が 「うーん,これはお皿ですね!」 だったとしたら,期待はずれもいいところで,そんなアプリは二度と使ってもらえませんよね.即アンインストールです.
つまり,ユーザが知りたいのはお皿の種類であったり製造メーカーに関する情報だったりするわけですが,これらをアプリが提供するためには「皿」が認識できるだけでなく,より細かい分類をしなければならないということになります..
さらに問題を難しくしているポイントとして,このような画像検索やAIアシスタントが一般物体を対象にしなければならないことが挙げられます. ユーザとしては,皿だけでなく,果物や動植物,芸術作品など様々なものを認識出来て欲しいというのは当然の要求ですよね.
したがって,これらの要求を満たすためには,広範かつ粒度の細かいクラスを認識できるクラス分類器が必要となります.
論文では,100,000 (100K) クラスというこれまでにない超巨大データセット Entity-Foto-Tree(EFT) を対象にして,この問題に挑んでいます.1
Challenge
巨大モデル学習の課題
一般的に,このような多数のクラス分類を学習することは困難です.論文では主な理由として次の2つが挙げられます.
- GPU のメモリ制約に起因するモデルサイズの限界
- 長い学習時間
GPU のメモリサイズは年々大きくなってはいますが,やはり一つのGPU上に載せられるモデルサイズ(パラメータ数)には限界があります. 例えば 4,096 次元のボトルネック層から100Kクラスの出力を得るとき,必要なパラメータ数は全結合層だけでとなって,実に4億以上ものパラメータが必要になります. CNNの場合,ボトルネック層の他にいくつもの畳み込み層がないと高い精度を実現できないため,通常の学習環境(GPU)ではとても扱いきれません.2
仮にこのような巨大なモデルをGPUに搭載できたとしても,次に待っているのは大量のパラメータ数に起因する長い学習時間です. Chen らの仕事によれば,18K ラベルを持つJFT300Mというデータセットを50台の NVIDIA K80 で 1 epoch 回すために2週間を費やしたという報告もあります.
本論文ではJFT300Mより5倍も大きなクラス数を扱うので,非常識的な計算リソースと学習時間がかかってしまうことは容易に予想されます.
既存手法
 では,これまではどのように学習を行っていたのでしょうか.
一つの解決策としては,巨大なクラスの全体集合をいくつかのサブセットに分け,サブセットごとにそれぞれ1つのモデルで細やかな分類を行う手法が存在します.
例えば,「皿」「果物」「犬」などを専門に扱うモデルを作って,それぞれに細かい分類を任せるような方法です.
では,これまではどのように学習を行っていたのでしょうか.
一つの解決策としては,巨大なクラスの全体集合をいくつかのサブセットに分け,サブセットごとにそれぞれ1つのモデルで細やかな分類を行う手法が存在します.
例えば,「皿」「果物」「犬」などを専門に扱うモデルを作って,それぞれに細かい分類を任せるような方法です.
確かに,この手法であれば,皿や果物の詳細を分類する専門のモデル(Specialist)を並列に学習させることができるので,リソースさえあれば学習時間は問題にならなくなるでしょう.
ただし,運用しなければならないモデルの数が増えることでシステムが複雑になりますし,推論時に必要とする計算リソースや実行時間が増加するデメリットがあります.
上記の課題から,本論文では1つのCNNモデルで大規模クラスを持つデータセットを学習することが目標となります.
Knowledge Concentration
では,本研究のアイデアである Knowledge Concentration を説明していきます.
アイデア
巨大なクラスラベル集合を持つデータセットを学習するために,Knowledge Concentration では複数の Teacher (Specialist) モデルから得られる知識を1つの Student モデルに集約して学習させることを考えます. つまり,Specialist たちの出力確率を参考にしながら Student を学習させることで,比較的小さな Student のCNNでも高い精度で推論を実現しよう,というアイデアとなります.
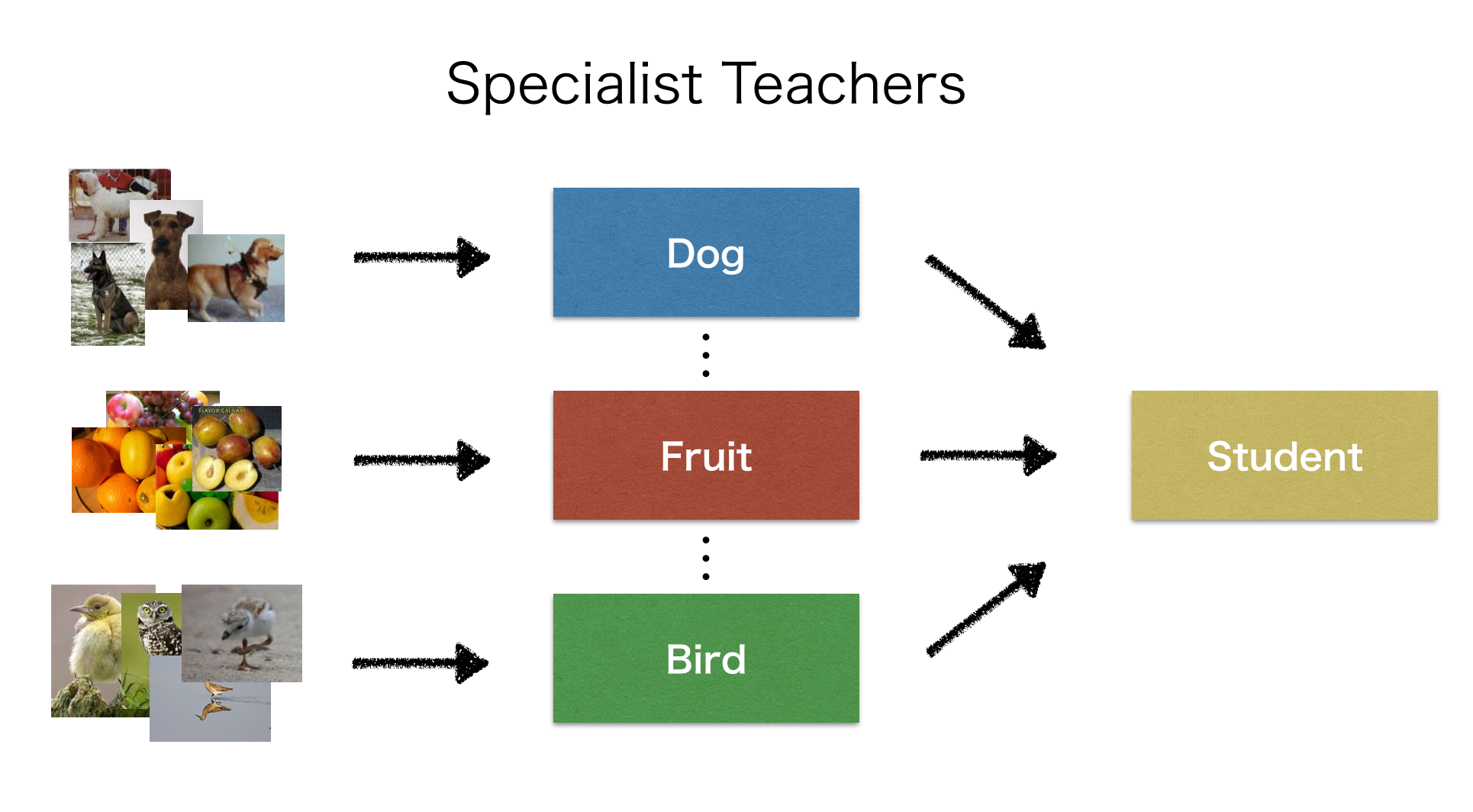
複数の Specialist を使うアイデア自体はオリジナルの Knowledge Distillation でも紹介されていました.
オリジナル論文で紹介されていたのは Specialist Student によるアンサンブル学習だったのに対して,Specialist を Teacher として1つの Student を学習させる Knowledge Concentration のアイデアは新しいものです.
Knowledge Concentration は,次の3つから構成されます.
- Multi-teacher Single-student Knowledge Distillation
- Structurally Connected Layers
- Self-paces Learning for Different Verticals
1 はアイデアの根幹である複数 Teacher による Knowledge Distillation 手法,2 は少ないパラメータ数でネットワークの容量を上げるために最終層に手を加えるアイデア,3 は異なる Teacher から十分に知識の転移を受けるための学習テクニックです. それぞれ紹介していきたいと思います.
Multi-teacher Single Student Knowledge Distillation
手法の説明に入る前に,vertical という用語の説明をしておきます.本論文では,各 Specialist モデルが担当する専門分野のようなものを vertical と表し, を担当する Teacher をにように書きます. Vertical はラベルの全体集合から意味的に近いものを取り出した部分集合です.例えば,「犬」を扱う vertical には「ダックスフンド」や「柴犬」のような細かい犬の種類についてのラベルなどが含まれています. ImageNet のような巨大なデータセットではラベルが階層的な木構造を持っているので,上位の階層で縦割りすることで意味的に近い集合を取り出せることから vertical と呼んでいるのだと思われます.
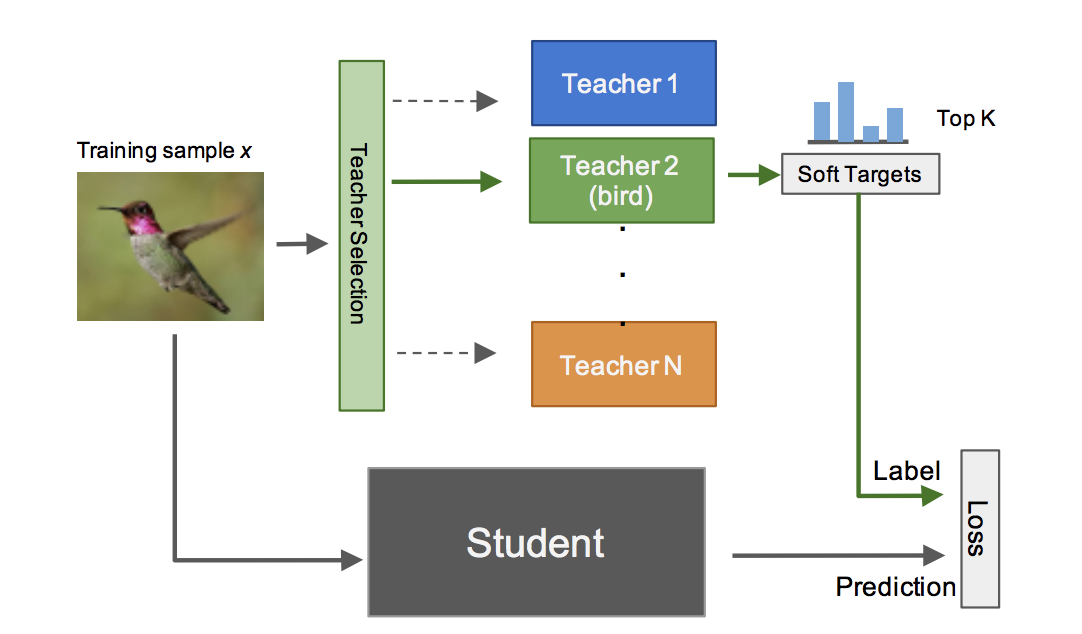
さて,本題に戻ります.Multi-teacher Single Student Knowledge Distillation による Student の学習の全体像は上図のようになっています. つまり,複数の学習済み Teacher が与えられたとき,入力に付与された正解ラベルががどの vertical に属するかを予測し,利用する Teacher を選びます. その後 Teacher から得られる予測確率(soft target)を正解ラベルとしてStudentを学習します.
Teacher の学習. Specialist Teacher の学習時は次のようなsigmoid cross entropy を用いて最適化します.
ここで,はバッチサイズ,はクラス数,は正解ラベル,は Teacher モデルの出力 logit です.
softmax ではなく sigmoidを用いるのは,階層的な構造を持つラベルの場合,一つの vertical に含まれるクラスラベルの関係を学習させたいからです. 例えば,「鳥」が含まれる vertical には「黒い鳥」というラベルも含まれている場合を考えます. 「黒い鳥」は「鳥」のサブタイプなので,もし「黒い鳥」の画像が入力された場合,「鳥」も「黒い鳥」も正解です. softmax を使った学習では一つの正解ラベル以外を排他的に扱ってしまうため,これらの意味的な階層関係を学習させることが困難です. 一方で,上式のようにsigmoid を使えば一つのクラスに関して二値分類を行うことになるため,階層的なラベルを持っていてもそれぞれの階層に対してうまく学習を行うことが出来ます.(「黒い鳥」だが「鳥」ではない,のような意味的な間違いが起こらない.)
複数の Teacher による Knowledge Distillation. Student は先程学習させた Specialist Teacher から受け取る予測確率(soft target)を使って学習を行います. 学習に利用される Teacher は入力のラベルから vertical を予測することで得られます.
Teacher が選ばれた後,次の式で Student を最適化します.
ここで,は Teacher から得られる予測確率,は student の出力 logit です.
このとき Teacher から得られる soft target は,top(ハイパーパラメータ)より下のクラスラベルや,選ばれた vertical に含まれないクラスラベルに関する予測確率を0に置き換えて Student の学習を行います.
Structurally Connected Layers
予測すべきクラスの数が大量に存在すると,CNN の最終層で使用する全結合(Fully Connected, FC) 層のパラメータ数がどうしても巨大になってしまいます. ここでは,パラメータ数を抑えながらモデル容量を増やすテクニックとして,Structurally Connected (SC) Layer を紹介します.
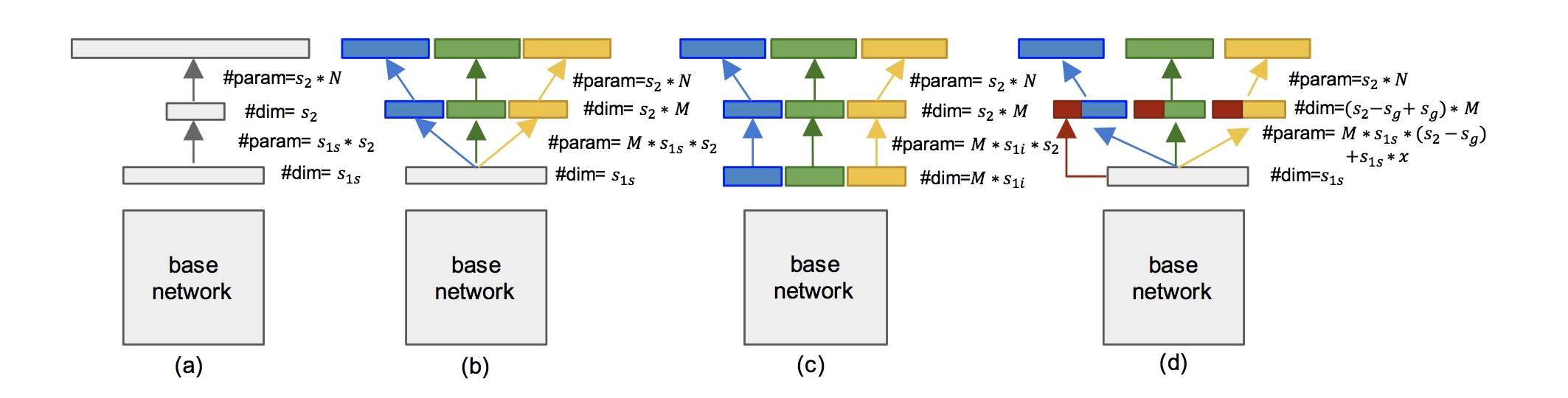
早速ですが,上図が本論文で使用される FC と SC を組み合わせた全パターンになります. 図を見るとなんとなくわかりますが,基本的なアイデアは,vertical ごとに FC 層を分割することで必要なパラメータ数を減らすというものです. FC層はその名が表すとおり,層間の全てのノードが接続されるため,単純に 入力の次元数 出力の次元数 のパラメータが必要となります. CNN を愚直に FC 層で実装したものが図中(a)に表されているパターン()です. このとき必要になるパラメータ数は,
です.
これでは 100K クラス分類の場合ものパラメータ数が最終層で必要となってしまい,モデル容量を上げるためにを増やそうとすると大量のパラメータが必要になります. そこで本論文では vertical ごとに FC 層を分割する Structurally Connected (SC) Layer を提案しています. vertical ごとに接続されるノードの範囲が分割されているので,FC層では必要だった他の vertical への接続がなく,その分パラメータ数を減らすことができます.
論文では,SC 層を使った3つの構成パターンを例示しており,これらを利用して実験を行います.3
- (b) :
- (c) :
- (d) :
(d) は に共有パラメータを導入することで分だけさらにパラメータ数を削減しています.
Self-paced Learning
Vertical によって内包されているクラス数はバラバラなので,Student に Knowledge Distillation を実施する際には vertical ごとに学習のペースを制御できることができれば,各 vertical の知識を十分に学習できることが期待できます.
Knowledge Concentration では vertical ごとに学習のペースを制御するための学習パラメータ を導入しています.
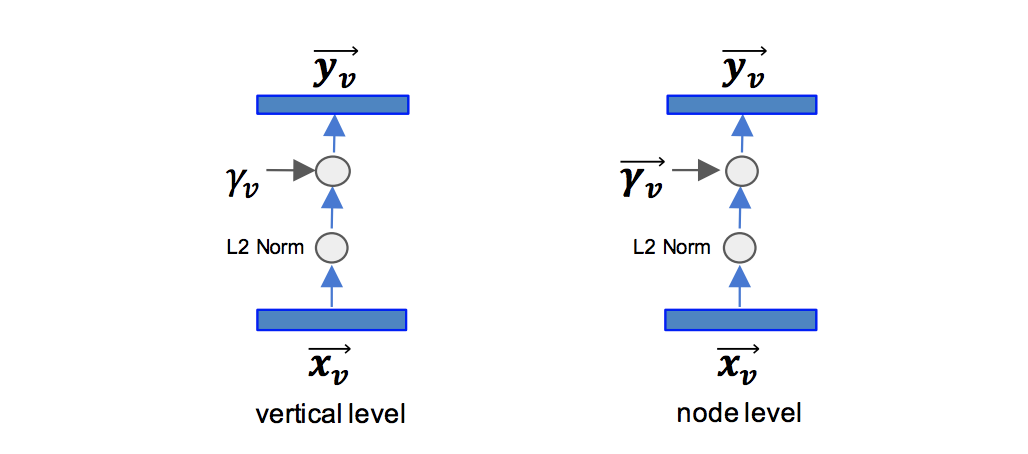
図のように, は最終層の番目のクラス/ノードのlogit に対してL2正則化をかけた上で以下のように適用されます.
この scaling factor はclass-level, vertical-level のどちらにも適用することができます. が大きくなることでバックプロパゲーション時に伝達する勾配が大きくなるため,学習率のような役割を果たすものと考えられます.3
Experiments
Knowledge Concentration による効果を検証する実験を解説していきます.
データセット
本実験では Entity-Foto-Tree (EFT) と呼ばれる巨大なデータセットを利用します. 詳細は以下のとおりです.
| Train Images | 400M |
| Test Images | 5M (50 images per class) |
| Classes | 100K |
| Verticals | 20 (aircraft, bird, car, dish, drink, gadget, hardware, home and garden, house, human, settlement, infrastructure, ingredient, invertebrate, landmark, mammal, sports, watercraft, weapon, wildlife, plant) |
その他の設定
- ネットワークは Inception-V2 ベースのCNN
- ベースラインは generalist な CNN を愚直に学習させたものと Specialist を使用
- (Knowledge Distillation 時に使用するTeacher モデルの予測確率の上位クラス数) は100
- 50GPU (P100) と25基のパラメータサーバで分散学習, フレームワークは Tensorflow
- Batchsize=64, 5 epoch,学習時間は大体40日くらい
- Specialist と Generalist のベースラインと公平に比較するために vertical ごとに平均精度(average precision)を計測
Multi-teacher Single-student の評価
まず,複数 Teacher による Knowledge Distillation の評価を見てみます. ここでは,異なる2つの構成のモデルに対してそれぞれDistillation あり/なし の場合で分類精度を予測しています.

FC4096-FC512 はSC層なしのアーキテクチャで,SC512-SC512 はSC層を導入したアーキテクチャです. どちらも4ポイント程度精度を改善できていることがわかります. 複数 Teacher による Distillation は確かに効果がありそうです.
SC 層の組み合わせ評価
提案したSC層を使って様々な組み合わせで評価を行っています.
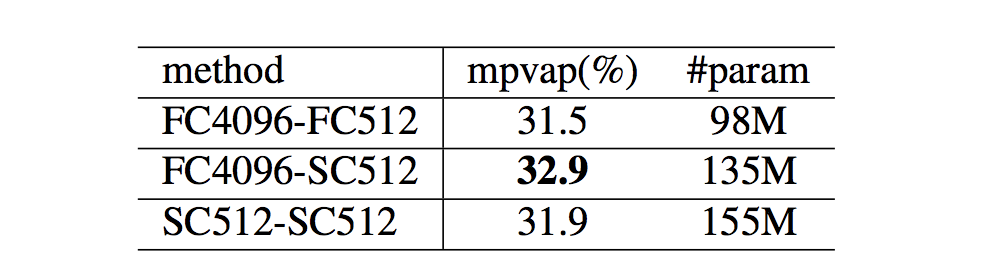
ここでは,上で紹介した (a) FC層のみ,(b) FC層-SC層 (c) SC層-SC層 で比較を行っています.(d) は (b) の一般化と言えるので,まずはシンプルにで評価を行っているのだと思います. 結果を見ると,提案手法の(b) FC層-SC層 の組み合わせが最も良い結果になっています.さらに,SC層だけで構成するよりもパラメータ数を抑えられているので,効率的にネットワークアーキテクチャの拡張も実現できていると解釈できます.
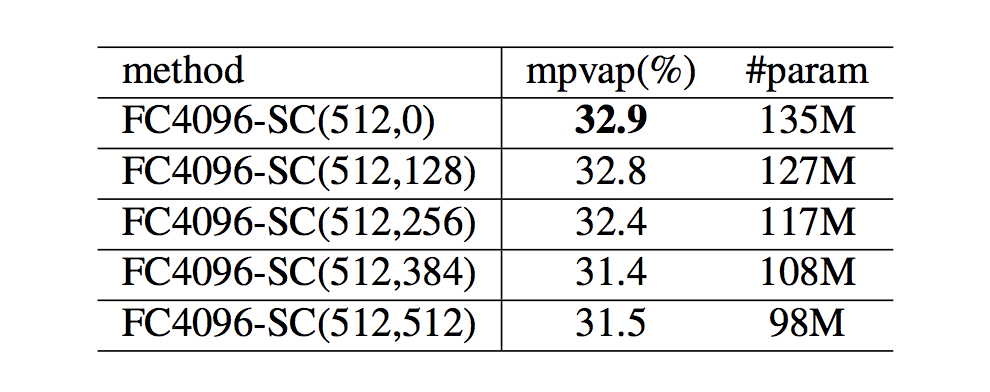
次に,最も優秀だった (b) タイプのアーキテクチャに対して共有部分を導入した (d) タイプのを変化させたときの評価です. 残念ながら,この手法ではの数が大きくなる=パラメータ数が減少するにつれて精度が悪化してしまっています. 提案した (d) タイプのアーキテクチャはパラメータ数は削減できますが,精度を保つことはできないようです.
Self-paced Learning の評価
提案されたself-paced learning は class あるいは vertical 単位で適用することを想定して設計されています. ここではclass, vertical それぞれのパターンでself-paced learning を適用したときの効果を実験しています.
実験パターンは以下の5つです.
- Vertical, Scaling Factor を で固定
- Vertical, Scaling Factor を学習,(平均,分散)=(10,1e-3) で初期化
- Class, Scaling Factor を学習,(平均,分散)=(10,1e-3) で初期化
- Vertical, Scaling Factor を学習,(平均,分散)=(,1e-3) で初期化
- Class, Scaling Factor を学習,(平均,分散)=(,1e-3) で初期化
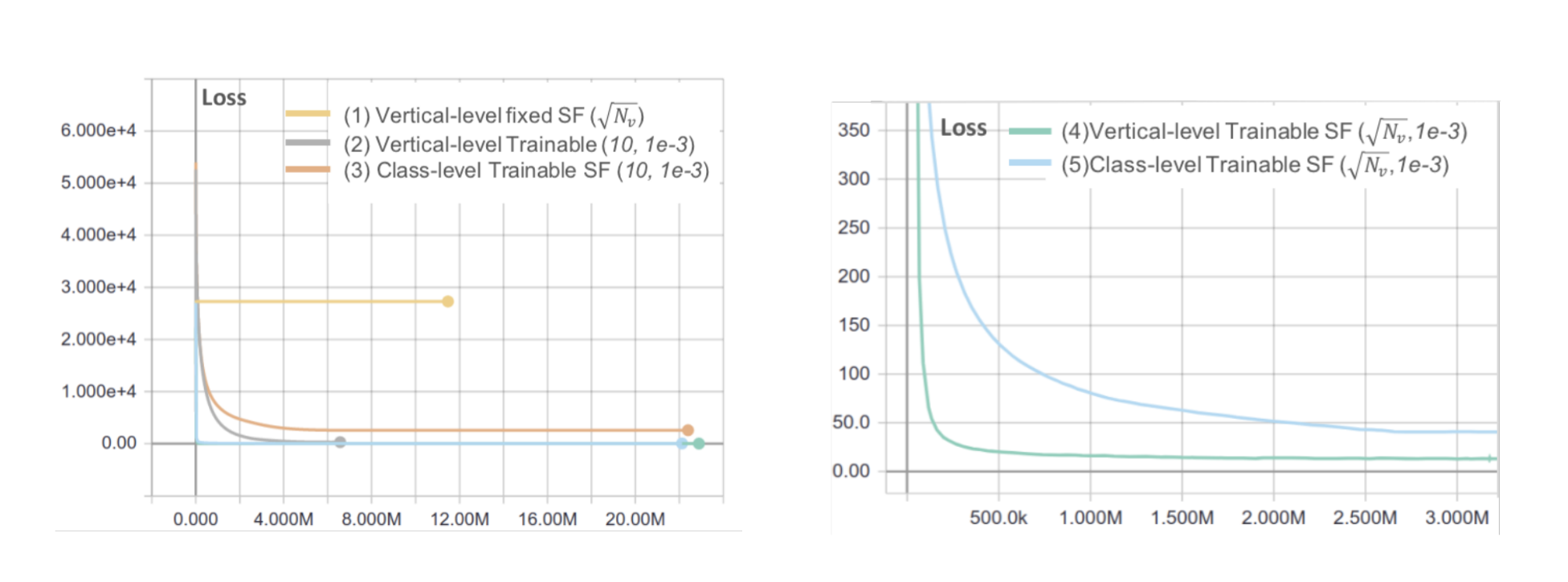 図は学習 iteration を横軸にとったときのlossの推移を表します.
結果として,Vertical 単位でScaling Factor を適用してで初期化を行う(4)で学習を行うパターンが最良であることがわかりました.4
図は学習 iteration を横軸にとったときのlossの推移を表します.
結果として,Vertical 単位でScaling Factor を適用してで初期化を行う(4)で学習を行うパターンが最良であることがわかりました.4
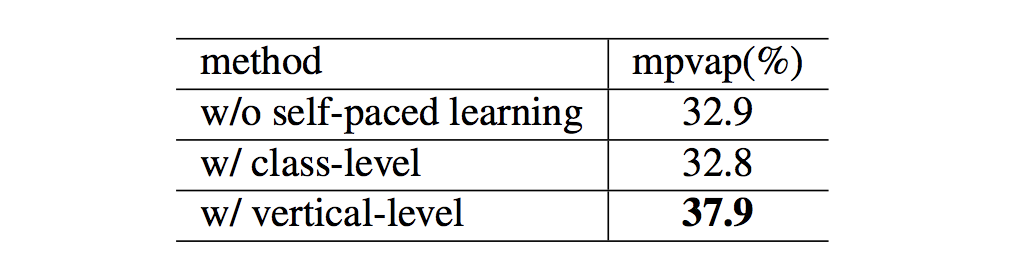
精度はどうなっているでしょうか.表は self-paced learning なし/ class level で適用 / vertical level で適用 の3つのパターンで精度を比較しています.学習時の損失の推移と同様に,vertical level で self-paced learning を適用した場合が他を引き離して良い精度を達成していることが確認できます.
Vertical ごとの推論精度比較
もともと本研究のモチベーションは,少ないパラメータで高精度の推論を行うことでした. この目標は達成できたのでしょうか?

表は,各パターンにおけるVertical ごとの推論精度をまとめたものです. はDistillation, は Self-paced learning をそれぞれ適用していることを表します.
確かに,提案手法の2つを適用するパターン(FC4096-SC512+D+S)が,Specialist 以外と比較したときは最良になっていますが, Specialist がVertical別に推論を行った場合と比較するとまだまだ差が大きいように思われます. これらの結果から本来達成したかったレベルの精度を実現できているかと言われると,微妙と言わざるを得ない印象です. ただし,Specialist モデル群の 1/20 程度のパラメータ数で,4割弱程度の分類精度を達成していることを考えると,効率的な学習は行えていると評価できるのではないでしょうか.
最後に,EFT データセットでの入力画像と推論結果の例を紹介します. 以下が入力画像と推論結果のクラスラベルの例となります.

これは推論に成功している結果の例なのでしょうが,Bird → Perching bird → Yellow-winged black bird のように粒度の大きいクラスから fine-grained なクラスまで予測することができています. このような推論が例えばスマートフォンのようなデバイスに収まるサイズで提供される時代になれば,冒頭で説明した例のように,AI アシスタントがオフラインでも幅広い物体認識を行えるようになるんでしょうか.
まとめと感想
読み始めた当初はシンプルなアイデアだっただけにすぐに読めると高をくくっていましたが,Multi-teacher ベースの学習やSC層の導入など,結構ぎっしり内容が詰まっていた論文でした. 自分の理解も甘いところがあり,少しこってりと書きすぎた感があります… また,これらの工夫をもってしても限られたパラメータ数で巨大データセットを学習するのは相当難しいようで,未だに発展途上の問題設定なのかなと感じました. ところどころ読み取れていない部分があるので,時間を見つけて記事を修正したいと思います.
Subscribe via RSS