FitNets: Hints for Thin Deep Nets
by maya
Sponsored Link
前回は,Distillation の初出論文を読んで,温度付き softmax による小さいモデルの学習について学びました. 今回は,深くて薄いネットワーク を学習するための手法を紹介している FitNets の論文を紹介します.
概要
本論文の貢献は以下にまとめられます.
- Teacher ネットワークの中間層の情報を伝達することで深くて薄い Student モデルを学習する手法を提案
- Teacher と Student でそれぞれ中間層の形状が異なる場合でも学習できるように,中間層間の変換をパラメタライズして学習
- 本手法を用いることで,Teacher モデルの10倍少ないパラメータのStudent モデルで SoTA の推論精度を確認 (CIFAR10)
アイデアはシンプルそうですが,得られる結果のインパクトが凄まじいですね. 楽しみながら読んで行きたいと思います!
この記事では前回に引き続いて,転移元のネットワークを Teacher, 転移先のネットワークを Student と表記します.
Motivation
優れた性能の Deep Learning モデルを軽量に利用したい
基本的には前回のKnowledge Distillationのモチベーションと同じモチベーションの研究です. つまり,小さなモデルサイズと高い精度を両立させることが研究の目的となります. とりわけ本論文では,ネットワークの深さに起因する恩恵に着目しています. これは既存の Model Compression や Knowledge Distillation にはなかった視点です.
一般的に,深いネットワークは以下の点で有利であると指摘されています.
- ネットワーク全体で階層的な表現を獲得できる
- 獲得した特徴を再利用できる
 可視化されたCNNの特徴マップ(引用元: Deep Learning (Goodfellow+))
可視化されたCNNの特徴マップ(引用元: Deep Learning (Goodfellow+))
ニューラルネットワークの深さに関する重要性は理論と実践それぞれで確認されています. 例えば Montufar らはネットワークの深さに従って指数的に表現力が向上することをいくつかの関数族で理論的に確認しました. ここで言う表現力とはニューラルネットで近似可能な関数の複雑さのようなものです.(Goodfellow本で言うところのCapacity) また,実践では ImageNet の SoTA が徐々に深くなっていることを挙げています.(2014年の論文ということもあり若干情報が古いです.) そういえば最近では10,000層を超えるDNNも登場していますね.
既存のモデル圧縮手法では,小さい モデルに知識を転移することが目的となっているため,深層学習で重要であるはずの深さにはあまり注目していませんでした. 例えば Model Compression では ラベルなしデータセットを使って Deep かつ Wide なモデルから Shallow かつ Wide なモデルへ知識を転移させていますし, Knowledge Distillation では Teacher と Student の深さはほとんどの実験で同じです.
この論文では,これまでの手法とは異なり,Teacher モデルよりも 深層かつパラメータ数の少ないネットワークを持つ Student モデルを学習させる手法を考えていきます. これによって,深層ニューラルネットワークの恩恵を受けつつ,パラメータ数を減らせるので,高精度で軽量な学習モデルの実現が期待できます.
Challenge
深いネットワークは学習が難しい
では深くて薄い(パラメータ数が少ない)ネットワークを用意してDistillation させればいいかというと,そういうわけにもいきません.
一般的に,深いネットワークは学習が難しいと言われているからです1. ニューラルネットワークは基本的にアフィン変換と活性化関数の組み合わせで構成されているので,そのパラメータの最適化は非凸・非線形な目的関数の最大・最小化によって成されます. また前述の通りネットワークを深くすることでモデルの表現力が大きくなるため,Overfitting しやすくなります.
Distillation の文脈で Student モデルを深くしていく場合にも,この最適化の課題からは逃れられません. 著者らは Distillation フレームワークでは Deep なネットワークを持つ Student モデルを学習することができる一方で, 上記に挙げたような深さによる学習の難しさの課題を解決できていないと主張しています.
FitNets
アイデア
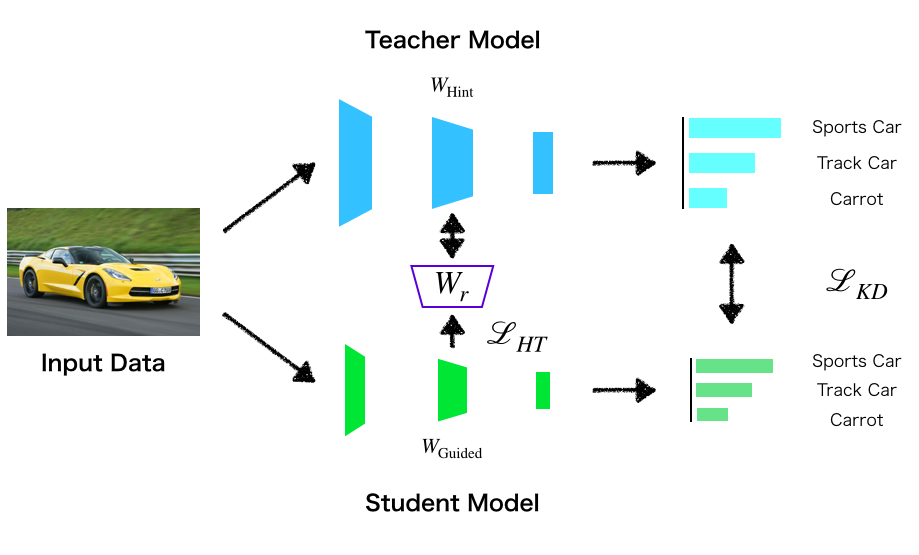
FitNets のアイデアは一言で言えば,Teacher と Student の中間層の出力を近づけることです. なぜ中間層に着目するのかという理由ですが,既存手法である Deeply-Supervised Nets や GoogLeNet が中間層に教師情報を与えることによって深層ニューラルネットワークの学習に成功していることから着想を得たものと考えられます.
 GoogeLeNet(Source)
GoogeLeNet(Source)
Hinton らの Knowledge Distillation は最終層出力から得られる予測確率の差を最小化するだけだったのに対して,FitNets では中間層出力についても Teacher を真似るように Student を学習させます. これによって,Teacher が良く汎化されたモデルであれば,より効率良く Deep な Student を学習することができるようになります. FitNets が対象にしているのはTeacher よりも深くパラメータ数の少ない Student なので,より深いネットワークを学習するためのテクニックの一つとしても捉えることができると思います.
Hint-Based Training
論文では Teacher の中間層出力を ヒント(hint) と呼び,Teacher と Student 間の中間層を以下の様に定義しています.
- Hint Layer
- Student にヒントを与える Teacher の隠れ層
- でパラメタライズ
- Guided Layer
- Teacher からヒントを受け取る Student (FitNets) の隠れ層
- でパラメタライズ
このときの (Hint, Guided) の組は何でも良いわけではなく,過剰な正則化を避けるために適切な組み合わせにしなければなりません. 前述の通り,隠れ層が深くなればなるほど抽象度の高い特徴を獲得するので,あまり深くしすぎるとヒントの柔軟性が損なわれて過剰に正則化が働く恐れがあります. 今回は真ん中くらいに位置する隠れ層を Hint, Guided として設定しています.
Hint と Guided が決まれば,下式で二乗誤差損失を計算して学習を行っていきます.
ここで,はそれぞれ Hint Layer, Guided Layer の出力テンソルであり,は,Guided Layer 出力を Hint Layer 出力の大きさに揃えるための regressor です(でパラメタライズ). 当然ですが,の出力テンソルの形状は一致している必要があります.
Regressor については全結合層ではパラメータ数が巨大になってしまうため,畳み込み層を利用して軽量な実装を実現しています. 具体的には,全結合層を使う場合,
のパラメータが必要となりますが, 畳み込みを使うことで
に削減することができます.
カーネルサイズは下記のように定めることができます.
学習アルゴリズム
FitNets の学習アルゴリズムは Hint Training と Knowledge Distillation の二段構成になっています.
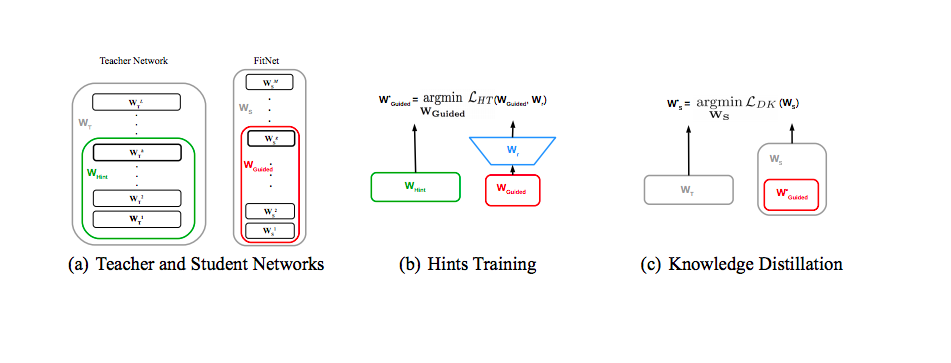
図は FitNets の学習工程全体を表しています. 大まかな流れは次のとおりです.
- 学習済み Teacher のパラメータ と 乱数で初期化した Student のパラメータを として設定
- 損失関数 を最小化して を学習 (Hint Training)
- 学習済み を として Student Network に適用
- Knowledge Distillation の温度付きソフトマックスで Student ネットワーク全体を学習
ポイントとなるのは,Hint Training 時は 入力層からまでを部分的に学習し,その後学習済みパラメータとして Knowledge Distillation の初期値として用いることです.
ちなみに,前回取り扱ったKnowledge Distillation の復習となりますが,Knowledge Distillation の損失関数 は次のように計算されます.
ここで, はクロスエントロピー, はクラスラベル, は入力に対する予測確率で, は温度係数です.
最終的なアルゴリズムは下図の様に記述されます.内容は上述したものと同じです.

Experiments
さて,FitNets の学習アルゴリズムを理解できたので,その効果の程を見ていきたいと思います.
CIFAR10 と CIFAR100 による評価
まずは定番データセットCIFAR10とCIFAR100 による評価です.
Teacher と Student のネットワーク構成は次のようになっています.
- Teacher
- (maxout) Convolution x3
- Full Connected x1
- Softmax Layer
- Student
- (maxout) Convolution x17
- Full Connected x1
- Softmax Layer
Student は Teacher よりも深く, 1/3 程度のパラメータ数になっています. また,Hint Layer は Teacher の2層目,Guided Layer は Student の 11層目をそれぞれ設定します. データセットに対してはフリップや回転などのデータ拡張を入れている点に注意してください.

Table1 と Table2 がそれぞれ CIFAR10 と CIFAR100 での実験結果 (accuracy) となります. 両データセットにおいて,FitNet が Teacher の精度を上回っていることが確認できます. つまり,パラメータ数を減らしてもネットワークを深くすることで良い精度を得られる,ということになります2.
また,既存のモデル圧縮手法と比較して,パラメータ数,精度ともに優れていることがわかります(Mimic Single, Mimic ensemble が既存のモデル圧縮手法)
(当時の)SoTA と比較しても遜色ない結果を出すことができています.すごい.
論文では Hint なんて使わなくても半分ずつ学習したらいいんじゃないの?という疑問にも答えていますが, 具体的なデータの掲載は無いためここで紹介するのは控えます.
類似の手法である Deeply Supervised Networks (DSN) との比較も行っています. DSN は中間層に直接 Softmax 層を追加することで,中間層に分類問題を解かせ,その予測確率のクロスエントロピーを最小化して学習する手法です. DSN を利用した場合,Accuracy は 88.2% となります. これは FitNets(91.6%) を下回る結果です, この理由としては,予測確率を使っていることで学習が不安定になるためであると説明されています.(Softmaxを利用することの弊害?) 一方で,FitNets の Hint ベースの学習は比較的滑らかな出力テンソルを扱うため良く汎化するそうです.
また,具体的なデータはありませんが,二段構成の学習アルゴリズムを一段にしてしまうと学習がうまくいかないと報告しています.
SVHN, MNIST
住宅番号の画像データセットである SVHN や手書き数字データセット MNIST でも評価を行っています. SVHN では 13層,MNISTでは6層の FitNets をStudent として用います.
結果は次の表にまとめられます.

CIFAR での実験と異なり,Error Rate で評価している点に注意してください.
SVHN ではTeacher を超えることができませんでしたが,パラメータを32%に削っていても精度がほとんど落ちていないことが確認されます.
MNIST では通常のソフトマックスクロスエントロピーロスを誤差逆伝搬だけで学習した Standard backprop や Knowledge Distillation だけで学習を行う KD の項が追加されています.
Teacher や他の手法と比較して最も良い精度を達成していることがわかります.
Analysis
最後に,この論文を通して着目してきた深さに関する分析結果を紹介します.
ネットワークの深さに関する分析
まずは,ネットワークの層数を増やした場合,学習にどのような影響が出るのかを実験で調べます.
実験では,ネットワーク層数以外の変数(Width, Height, 計算回数など)をすべて固定にし,層を増やしていったときの変化を確かめています.
比較対象は,通常の誤差逆伝搬のみの学習 Back Propagation,Knowledge Distillation,Hint Training の3つです.
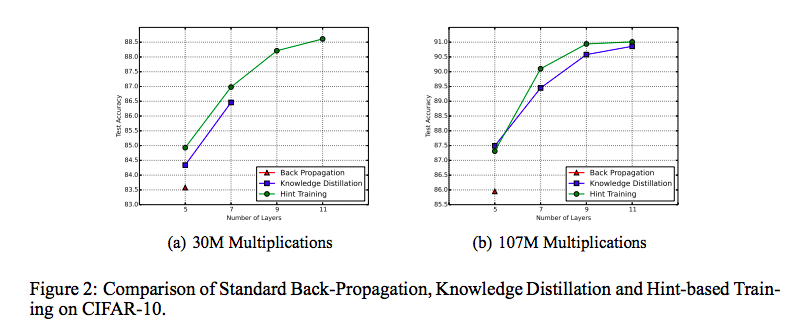
図は,計算回数を30M, 107M にそれぞれ固定したときの層数と精度の関係を表しています.
実験結果を見ると,Back Propagation は層数7以降では計算回数が増えても学習できていません.
深さが増えることで学習が難しくなり,限られた計算回数では収束しないことが原因です.
一方で Knowledge Distillation は計算回数が30Mのとき7層まで学習が収束しますが,それ以降の層数になると学習できていません.
この結果から,Knowledge Distillation を利用したとしても,深層ネットワークを効率良く学習させることが難しいことがわかります.
今回の提案手法である Hint Training は,Knowledge Distillation を行う前の事前学習という位置づけですので,
良い初期値を与えることで Knowledge Distillation の学習を促進する効果が期待できます.
実際,実験結果を見ると,層数が増えても限られた計算回数で収束させることができています.
テスト精度も改善していることから,提案手法は Knowledge Distillation よりも優れた正則化効果があると言えます.
まとめると,
Hint Trainingを用いることでより深いネットワーウを学習させることができる- 固定の計算回数では,深層モデルのほうが浅いモデルよりも良い精度を獲得できる
ことが確認できました.
モデルの性能と学習効率のトレードオフ
Knowledge Distillation や Hint Training の重要な目的は軽量で性能の良いモデルの実現でした. では,性能を担保しながら,どこまでネットワークを削れるのでしょうか?
実験では,Teacher に対する FitNet の圧縮率を変化させた場合の性能と推論速度を調べています. 以下がその結果となります.
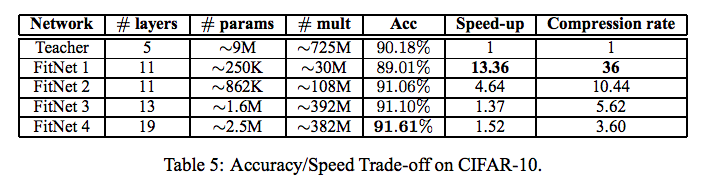
すべての FitNet が Teacher よりも速い速度で推論することができていますが,スピードと精度との間にはトレードオフが存在していることもわかります. どのFitNet のパターンを選ぶのかはアプリケーションの要求に依存していますが,全体的に精度・推論速度・パラメータ数で良い結果を出せているのが提案手法の利点であると論文では述べられています.いずれにせよ,実際に利用する際は要求が何であるかを明確に定義していくべきだと考えられます.
感想
今回は中間層の状態に着目して深層の Student を学習する FitNets を紹介しました. 実験もしっかり行われていて,章立てなど論文の構成としても大変参考になるとても良い論文だったかと思います.
ただ,深層ニューラルネットワークの SoTA がたかだか20層だったりして,数年前の論文にもかかわらず”時代”を感じさせる論文でもありました. それだけ Deep の世界は発展が著しいということでしょうね…
次の更新は来年になると思います.
みなさま,良いお年をお迎えください.
Subscribe via RSS