Deep Mutual Learning
by maya
Sponsored Link
新年明けましておめでとうございます. Distillation 企画の2019年一発目は,Deep Mutual Learning です. こちらは実を言うとDistillation に分類すべきかは微妙なところなのですが,Student の学習時に Teacher は不要という大胆な主張をしている面白い論文です.
概要
本論文の貢献は次のようにまとめられます.
- Teacher モデルを必要とせず,Student 同士が教え合う
deep mutual learning (DML)を提案 - 各 Student の予測確率同士のKL ダイバージェンスを近づけていくことで学習を行う
- CIFAR100, Market1501 における実験で Teacher を利用する Distillation よりも良い性能を達成
これまで紹介してきた Distillation の手法は,大きいモデルから小さいモデルへの知識の転移を目的としていました. つまりStudent に知識を転移するためにはよく学習された Teacherが必要だったのですが,この論文では Teacher すら必要ないという主張を展開しており,なかなか刺激的です.
それでは論文を読んでいきたいと思います.
Motivation
コンパクトかつ高性能なモデルの実現
Deep Learning はこれまでの機械学習モデルを凌駕する性能を達成できますが,その反面大量のパラメータを必要とするため推論時間・メモリ使用量の面でアプリケーションの要求を満たせない可能性があります.
そこで,なるべく小さなネットワークで高い性能を達成したいというのが研究の目的です.
Related Work
小さく高性能なモデルを実現するための手法はすでにいくつか提案されています.
このうち,論文で着目しているのは Distillation で,提案手法も Distillation の類似手法として位置づけられています.
Distillation: Student が Teacher をマネて学習する
Distillation は,小さなネットワークを持つ Student モデルを学習するために,よく学習された Teacher モデルから知識を取得します. この Teacher モデルは大抵 Student モデルよりもパラメータ数の大きいネットワークを持っています.
Distillation による学習は,Student の学習時に Teacher の出力情報をマネる(mimic)項を目的関数に追加することで行われます. 既存手法の違いは,Teacher のどの部分をマネるかの違いであると言えます. 具体的には,以下の2種類が存在しています.
いずれにせよ,既存の手法では,学習済みのTeacher を必要としていました.
Deep Mutual Learning
Student が互いに教え合って学習
本論文では,Teacher を使わない学習方法 Deep Mutual Learning (DML) を提案しています.
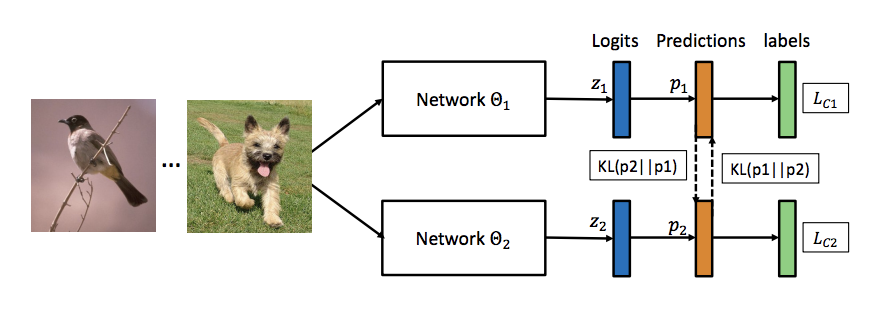
直観としては,一つのデータセットについて複数の Student モデルを学習します. 基本的にこれだけです.
1つの Student の目的関数は次の2つの損失項からなります.
- supervised learning loss
- クラスラベルに対する予測確率のソフトマックスクロスエントロピー
- mimicry loss
- 他の Student の予測確率とのKLダイバージェンス
Formulation
それでは,上の2つの損失による学習を式で表していきたいと思います. ここでは2つの Student モデルでクラス分類を学習することを考えます. の選び方は基本的に自由です.後の実験ではヘテロな構成で良い結果を達成できることを示します.
ある入力に対するのクラスについての予測確率は,
ここで,logit はソフトマックスへの入力テンソル(次元)の次元目の値です.1
supervised learning loss,つまり正解ラベルに対するソフトマックスクロスエントロピーは次のように計算できます.
ここでは onehot ラベルの番目の要素で, 0 ()か 1 ()の値を取ります. 既存の Distillation のように温度付きソフトマックスを使うわけではなく,通常のソフトマックスで学習を行います.
次に,から得られる予測確率を使って mimicry loss を表します. DML では,同じ入力に対する Student 同士の予測確率を近づけるためにKL-ダイバージェンスを最小化します.
したがって,Student全体の目的関数は以下のようになります.
同様に, に関しても,
となり,これらを相互に最適化していくことで良いの獲得を目指します.
学習時は,それぞれに学習率を設定し,順番にパラメータを更新していきます.(下図参照)

個の Student への拡張
簡単のために,上記では2つの Student での Mutual Learning を考えましたが,もちろん任意の数の Student について拡張することができます.
今,個の Student が与えられているとき, での損失は次のようになります.
つまり,第二項については自分以外の各 Student とのKL-ダイバージェンスをとって平均を取るだけです. 平均を取る理由は,学習の真の目的が各 Student の予測確率の傾向を似せることではなく,教師あり学習の対象となるタスクの精度を上げることなので,第二項の影響を大きくしすぎないためであるとされています.
このとき,もっと楽をする方法として,事前に他の Student の予測確率を平均化してしまう手法が思いつきます. しかし,この手法では予測確率のエントロピーが下がってしまい,うまく学習できないことがこの後の実験で示されます. ここでは式だけを紹介しておきます.
アンサンブル学習との違い
DMLは複数の Student で学習を行うため,アンサンブル学習と何が違うのか?という疑問は当然湧き上がります. この観点で,著者らは,DMLでは Student が互いに似るように学習を行うため従来のアンサンブル学習とは異なると主張しています. つまり,多様性を増すことは目的ではなく,むしろ減らす方向に最適化されるため,アンサンブル学習とはゴールが異なる学習方法と捉えられます.
Experiments
DML による精度改善を実験で確かめる実験を紹介します.
Dataset & Settings
今回の実験では2つのデータセットを用いて実験を行います.
- CIFAR100
- 100 クラスの一般画像分類用データセット
- 32x32, (train, test) = (50k images, 10k images)
- 200 epoch
- learning rate decay (60 epoch ごと)
- mini-batch size: 64
- data augmentation (random crop, horizontal flip)
- Market-1501
- 人物再照合タスク向けのデータセット
- 全 32,668 images, (train, test) = (751 IDs, 750 IDs)
- 学習時: 751 クラス分類を学習
- 推論時: 特徴抽出器として利用.クエリ画像との最近傍マッチングで人物再照合タスクを解く
- 10,0000 iteration
- Adam ()
- mini-batch size 16
モデルとパラメータ数は次のとおりです.

CIFAR100 での評価
まず,CIFAR100 での実験結果を紹介します. 実験は,4つのモデルのさまざまな組み合わせで,独立に学習した場合と,DML を用いた場合とで比較を行っています.
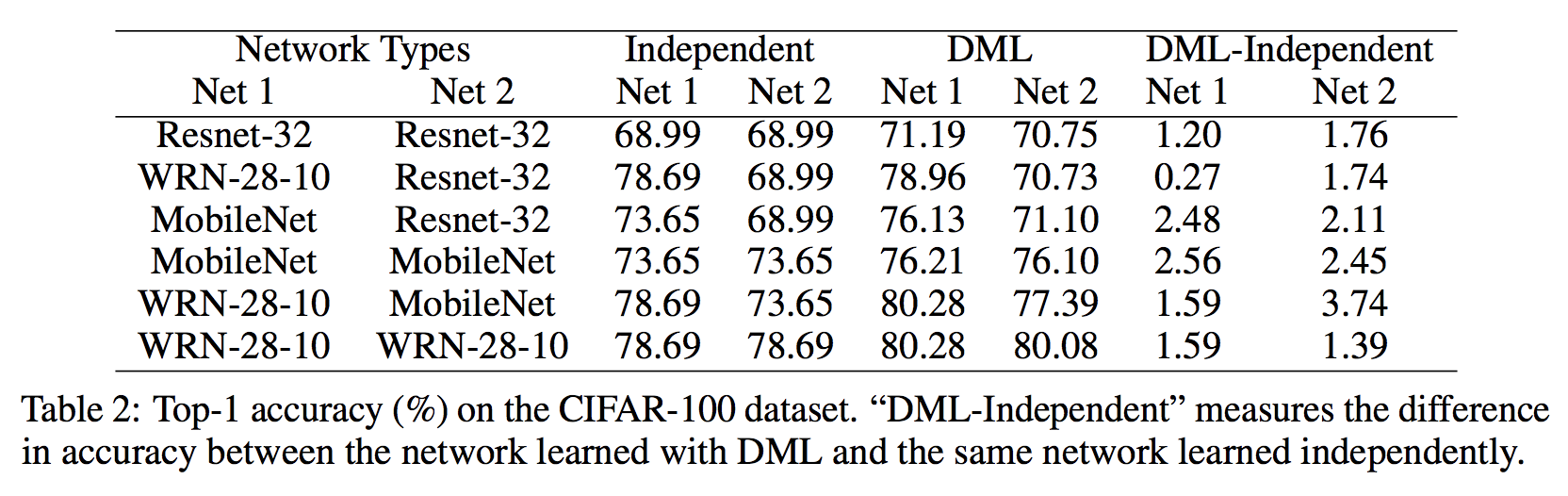
表からわかる結果として,まずすべての組み合わせにおいてDMLで精度改善を確認できます. また,小さいネットワーク(Resnet-32, MobileNet)はDMLの恩恵を受けやすいことも挙げられます.
Market-1501 での評価
続いて,Market-1501 での評価を見てみます.
実験は MobileNet を2つ組み合わせた場合の mAP と Rank-1 accuracy を測定しています.
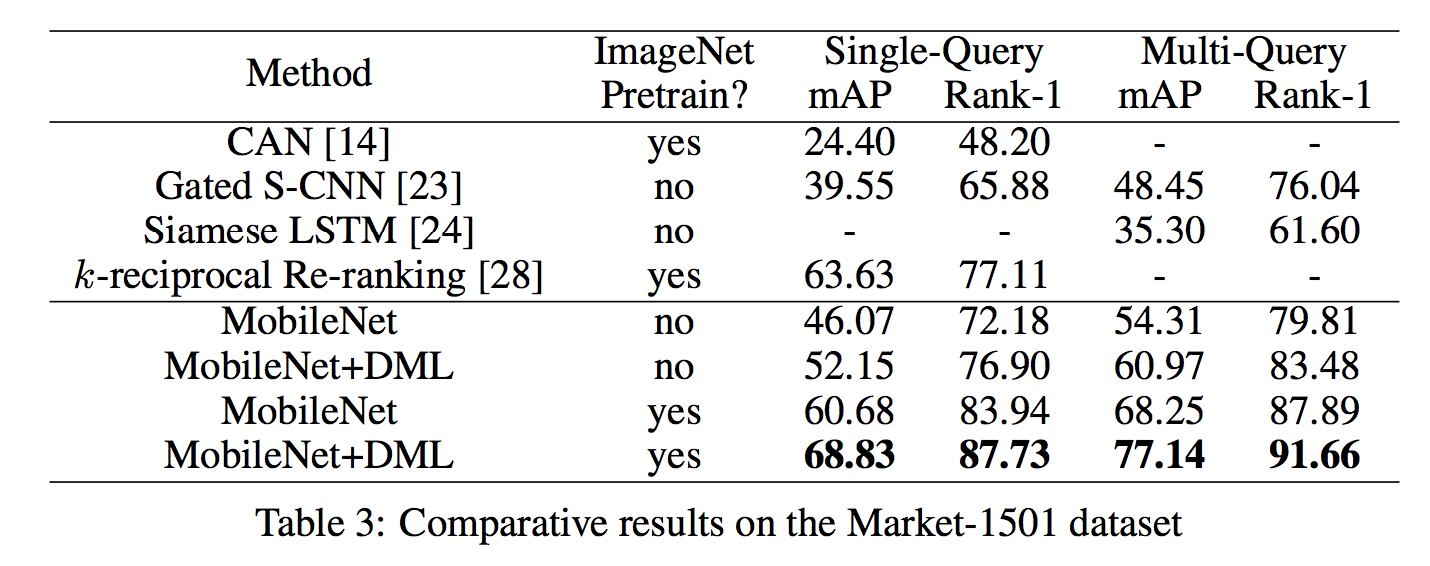
こちらでも DML を用いた場合に最も良い結果を得られています. ImageNet による Pre-training を用いることで,比較対象の中でベストスコアを達成できていることがわかります.
Distillation との比較
次に,DML と深く関連している Distillation との比較を行います.
先程の実験と同様に,CIFAR100 と Market-1501 における Independent Learning, Distillation, DML の3つの精度を比較しています.
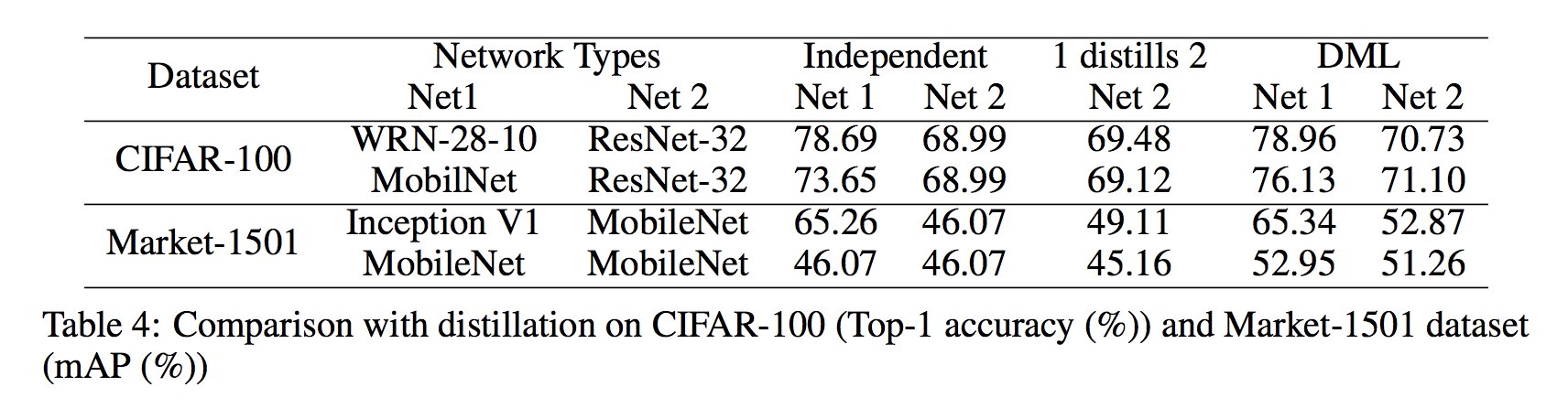
この実験結果では,ほとんどのケースで Distillation は Independent と比較して精度改善できていますが,DML はそれを凌ぐ改善効果を示しています.
また,MobileNet 同士を組み合わせても Inception V1 と比較して良い結果を得られていることから,巨大な Teacher がいなくとも精度をブーストできることがわかります.
つまり,Distillation のように巨大なモデルを用意しなくても,一つの精度改善手法として十分 DML は効果を発揮することが期待できます.
Student モデル数の比較
これまでの実験では Student の数は2つだけでしたが,それ以上に増やすとDMLの効果はどう変化するのでしょうか.
下図は,Student モデルを1~5 にスケールさせたときの DML と個別に学習した場合との精度の平均と標準偏差を表しています.

DML は Student 数が増えるとともに平均精度が向上していることが確認できています. また,標準偏差が徐々に小さくなっていることから,学習を安定化する効果もあるようです.
続いて,Student 数を増やしてアンサンブルで推論させたときの精度の変化を見てみましょう.
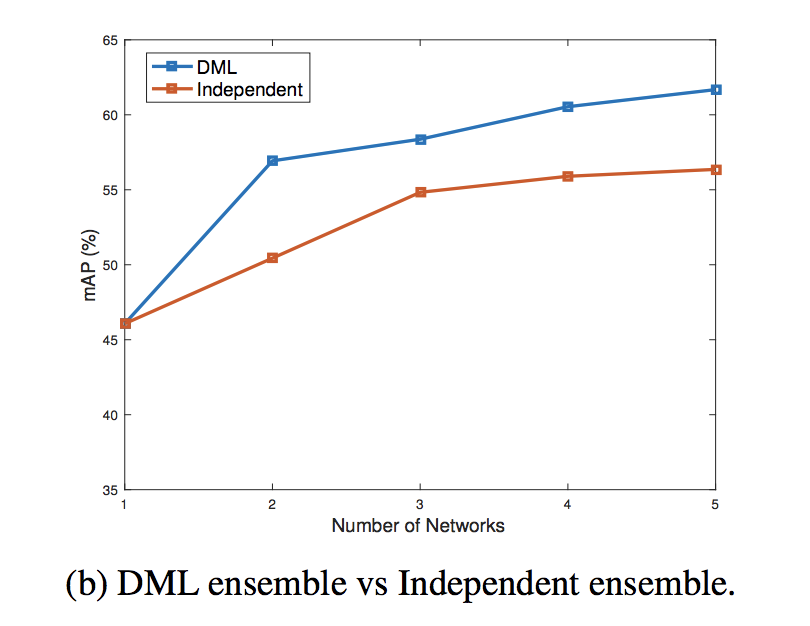
個別に学習させるよりも,DML を利用してアンサンブルさせたほうが良い精度を達成できています.
まとめると,DML ではできるだけたくさんの Student 数で学習・推論を行うほうが良い精度を獲得できる,ということがわかりました.
なぜ DML はうまくいくのか?
ここからはDMLがうまくいく原因の分析を紹介します.
Chaudhariら や Pereyra らの先行研究では,事後確率のエントロピーが高いほうが,ロバストな最適解,つまりよく汎化するパラメータに到達する可能性が高いことが示されています.
今回の DSL による peer-training がうまくいく要因も,この事後確率のエントロピーの高さであると著者らは主張しています.
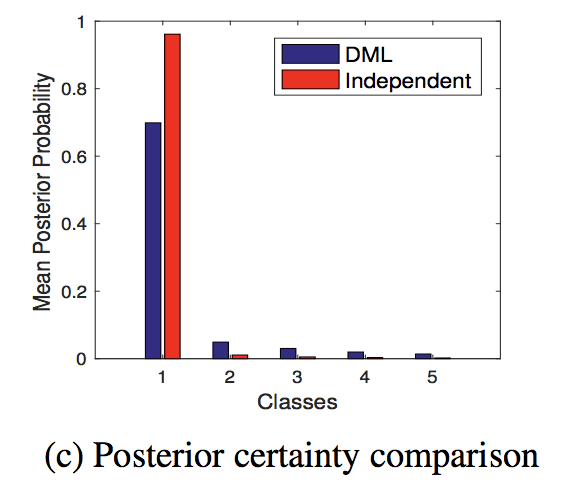
図は DML と通常の学習モデルの事後確率の分布を表しています. この分析結果から,DML による事後確率は極端に決定的な出力ではなく,高エントロピーであることがわかります.
もう一つの分析として,上で紹介した個の Student によるDML の2つの方法の比較を行っています.
つまり,先にとして他のStudentの事後確率をまとめるか否かという2種類です.
ここでは,として計算する方法をDML_e, と表記します.
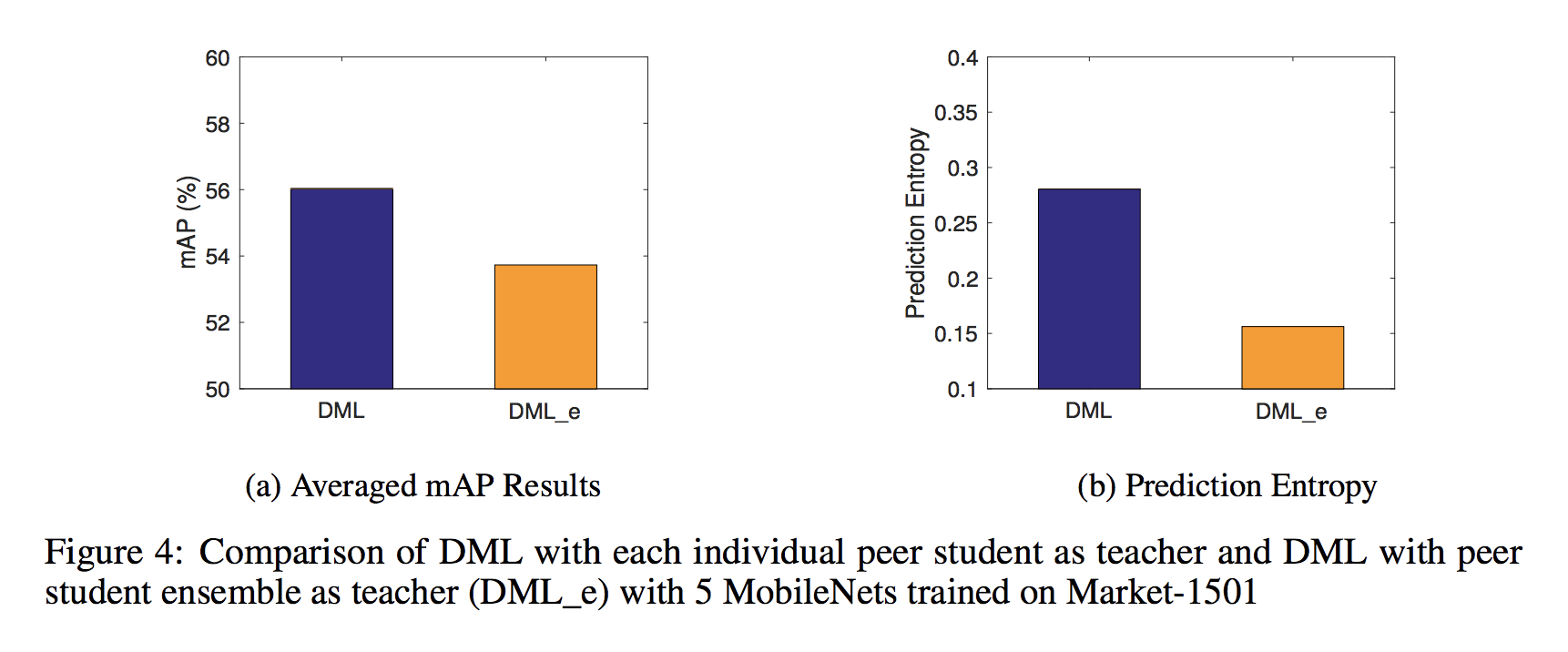
この実験によればDML_e によるモデルは通常のDML よりも劣ってしまうことがわかります(図中左). この理由として,として事後確率をまとめてしまうと,高い確率は高く,低い確率は低く平均化されてしまうため,全体としてのエントロピーが低くなってしまうことが挙げられます. この証拠となっているのが図中右の予測確率のエントロピー比較となります.
横着せずに Student ごとにKL-ダイバージェンスを計算することが重要ということなのでしょう.
まとめと感想
この記事では,Teacher を必要としない複数 Student による効率的な学習方法 Deep Mutual Learning を紹介しました. これまで常識と思われていた高性能な Teacher から Distillation を行うというフレームワーク自体を考え直すという発想が斬新で,読んでいてなかなか面白い論文でした.
実験結果も充実していて,Abst を読んだ時点で自分が持っていた疑問にほとんど答えてくれていました. 自分が書くときにも,このように論理構成がしっかりしている論文にしたいものです.
まだまだ読みたい論文は溜まっているので,冬休み中にもう一本まとめたいと思います. 本年もどうぞよろしくお願いいたします.
-
論文中では is the output of the softmax layer in とありますが,おそらく誤植だと思います. ↩
Subscribe via RSS